Ralentissement envoi et notification 04/11/2025
Postmortem
Post-mortem incident — 3 & 4 novembre 2025
Contexte
Le 3 novembre, à 11H00 CET une coupure électrique survenue dans notre datacenter MRS1 (infogéré par notre sous-traitant Evolix) a entraîné l’arrêt brutal d’une partie de notre infrastructure, incluant le serveur SQL principal, resté hors service pendant plusieurs heures.
Les mécanismes de bascule automatique (failover) vers le serveur miroir hébergé sur MRS2 (autre datacenter) ont bien été activés, mais un dysfonctionnement est apparu lors de la procédure. La remise en service prématurée du serveur principal et les interactions entre les deux instances ont provoqué une instabilité de synchronisation jusqu'à 16h45.
Une seconde instabilité est survenue le 4 novembre, à 09H30 CET lors du retour en mode nominal des deux serveurs.
Au total, ces deux incidents ont entraîné une dizaine de coupures réparties sur 48 heures, impactant notre plateforme et nos API :
· API HTTP : environ 2 heures d’indisponibilité cumulée
· API REST : environ 3 heures d’indisponibilité cumulée
De forts ralentissements d’envoi voire des accès refusés aux requêtes API ont été observés sur les plages horaires concernées, détaillées plus bas dans ce post-mortem.
Chronologie détaillée
📅 Lundi 3 novembre
- 11h01 — Coupure électrique sur une baie MRS1.➜ Arrêt d’une trentaine de serveurs physiques et d’une centaine de serveurs virtualisés.
- 11h05 — Bascule automatique sur le serveur miroir (infrastructure identique sur MRS 2).
➜ Service initialement rétabli.
- 11h10–11h20 — Le serveur principal, redémarré brutalement, lance un check et une réparation des tables SQL.➜ Accès bloqué aux données, erreurs en timeout.➜ Le système considère à tort le serveur comme opérationnel et tente une reprise de main.
- 11h20–11h58 — Période instable : bascules successives entre les deux serveurs, perte d’efficacité.
- 11h58 — Bascule forcée sur le serveur miroir.➜ Saturation du nombre de connexions (atteinte de la limite max).➜ Déconnexions et ralentissements.
- Jusqu’à 16h45 — instabilités latentes jusqu’à modification des configurations proxy par notre infogérant Evolix.➜ Réinitialisation de la limite de connexions et stabilisation du service.
Notre serveur primaire, de MRS 1, et ses tables SQL ont mis 6 heures à récupérer leurs états de fonctionnements, puis 3 heures pour rattraper la réplication.
Fin du premier incident : Remise en place des deux serveurs durant la nuit, mais la production est restée sur le serveur miroir.
⏱ Durée d’impact :
- API HTTP : ~1h
- API REST : ~2h
📅 Mardi 4 novembre
- 09h30 — Vérification de la réplication et retour à une situation nominale.➜ Les serveurs semblent synchronisés.
- 09h35 — Nouveau crash du serveur principal 5 secondes après la bascule sur le serveur principal.➜ Redémarrage de 6 heures, bascule d’urgence sur le miroir.
- Cause immédiate : Mauvaise configuration SQL.
➜ Les paramètres modifiés à chaud n’étaient pas persistés après crash (retour à des valeurs par défaut trop faibles).
- Retour sur miroir
➜ Le service reprend mais avec files d’attente et reports d’envoi importants.
- 09h30–13h00 — Service instable avec files élevées.
- 13h00 fin des problèmes de serveur.
- 14h00 — Action humaine de relance des campagnes marketing programmées.➜ Génération de doublons de Delivery Reports (DLR), provoquant un ralentissement temporaire jusqu’à la fin de la purge des DLR.
- 18h00 — Rétablissement complet du service.
⏱ Durée d’impact :
- API HTTP : ~1h
- API REST : ~1h
Analyse des causes
Impacts sur nos API
Aucun impact de sécurité n’a été constaté.
Graphiques de nos envois de SMS et des coupures
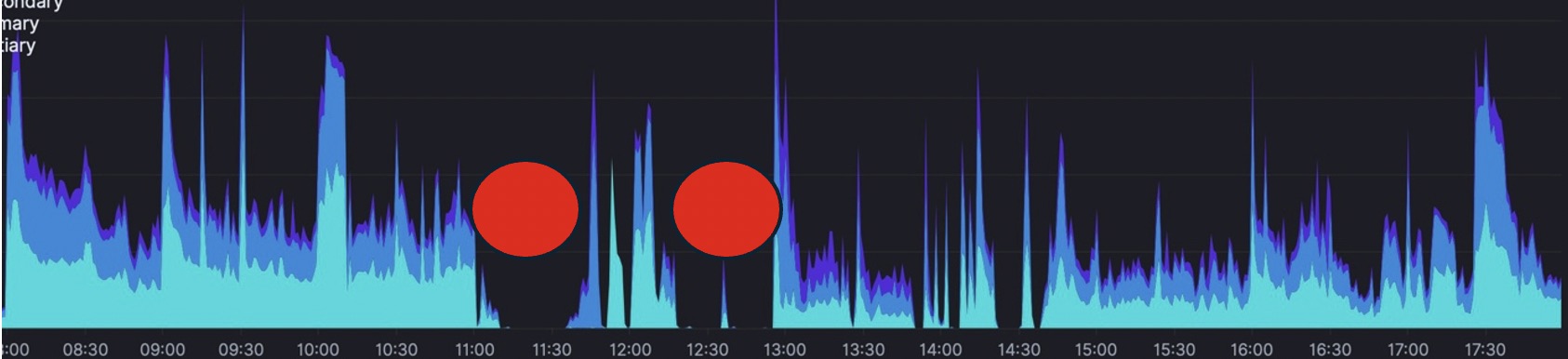 Journée du 3 novembre 2025 : ➜ Ouvrir
Journée du 3 novembre 2025 : ➜ Ouvrir
 Journée du 4 novembre 2025 : ➜ Ouvrir
Journée du 4 novembre 2025 : ➜ Ouvrir
Commentaire :
Nous avons observé des SMS non envoyés pendant les plages horaires impactées par l’incident de coupure d’API. Certains rejets API ont pu être constatés durant les périodes « down ». Les SMS acceptés ont été renvoyés dès que possible.
Les clients utilisant des SMS OTP et des SMS à haute priorité ont été privilégiés lors des renvois, afin de minimiser le temps de livraison de leurs messages par rapport aux autres envois de la plateforme.
Les DLR et MO ont été rejoués dans la mesure du possible.
Actions correctives immédiates
✅ Réinitialisation de la limite de connexions SQL & Proxy (Evolix)
✅ Correction de la configuration SQL pour rendre les paramètres persistants
✅ Forçage de la réplication sur le miroir avant retour en nominal
✅ Vidage et contrôle complet des files d’attente et DLR
Actions préventives
🔸 Mise en place d’une vérification automatique de cohérence SQL avant reprise de main.
🔸 Revue complète de la configuration de bascule et réplication (tests sous charge et en conditions de panne).
🔸 Ajout d’un système d’alerte sur les limites de connexions et sessions.
🔸 Persistance systématique des paramètres SQL critiques.
🔸 Mise à jour de la documentation des automatisations du process de bascule contrôlée.
Conclusion
L’incident initial, d’origine électrique, a révélé des points de fragilité dans la gestion automatique du basculement et la persistance des paramètres SQL.
Les correctifs et améliorations engagés doivent permettre d’éviter toute instabilité future lors des opérations de reprise ou de maintenance planifiée.
Nous sommes pleinement conscients de l’impact que ces incidents ont pu avoir sur vos services et en assumons l’entière responsabilité et avons activé nos garanties SLA.
Notre service support ainsi que votre chargé(e) de compte restent bien entendu à votre disposition pour toute information complémentaire.
Nous poursuivons, avec notre infogérant, la mise en place de correctifs afin de renforcer la réactivité et la fiabilité de nos équipes face à ce type d’incident.
Nous vous présentons, une nouvelle fois, nos plus sincères excuses pour la gêne occasionnée.
Resolved
Update
Update
Update
Update
Update
Nos équipes techniques travaillent sur le sujet.
****************************************************
We apologize for the inconvenience: despite our best efforts, slowdowns persist.
Our technical teams are working hard to get everything back up.
Monitoring
Nous rencontrons actuellement un ralentissement temporaire sur l’envoi des SMS et des DLR.
Soyez assuré : tous les messages sont bien générés et seront délivrés, avec un délai légèrement supérieur à la normale.
Type de problème : Ralentissement
Date début : 04/11/2025
Heure début : 09:50 CET
Heure de fin : ---
Description : Ralentissement des envois et des DLR
Nous vous prions de nous excuser pour la gêne occasionnée.
Cordialement
L'équipe smsmode©
https://www.smsmode.com
https://statuspage.smsmode.com
Mail : support@smsmode.com
tel : 33 (0)4 91 05 64 62
---------------------------------------------- English follows
Dear customer,
We are currently experiencing a temporary slowdown in the sending of SMS and DLR messages.
Please be assured that all messages are being generated and will be delivered, with a slightly longer than normal delay.
Type of issue: Slowdown
Start date: 11/04/2025
Start time: 09:50 CET
End time: ---
Description: Slowdown in sending and DLRs
We apologize for any inconvenience this may cause.
Best regards,
The smsmode© team
https://www.smsmode.com
https://statuspage.smsmode.com
Email: support@smsmode.com
Tel: 33 (0)4 91 05 64 62